2024.05.31 - [프로그래밍/강화학습 (RL)] - 틱택토 강화학습 (Tik-Tak-Toe RL) - [정보과학융합탐구 - 5월 과제]
틱택토 강화학습 (Tik-Tak-Toe RL) - [정보과학융합탐구 - 5월 과제]
2024.04.08 - [프로그래밍/강화학습 (RL)] - 틱택토 강화학습 (Tik-Tak-Toe RL) - [정보과학융합탐구 - 4월 과제] 틱택토 강화학습 (Tik-Tak-Toe RL) - [정보과학융합탐구 - 4월 과제]2024.03.28 - [프로그래밍/강화학
olzl07.tistory.com
저번 달에는 사람 2명이서 틱택토를 플레이 할 수 있도록 하는 환경을 구축해주었습니다. 이번 달에는 앞서 구현했던 환경을 보완하고 수정해준 뒤, 강화학습 알고리즘을 짜보도록 하겠습니다.
환경 수정
저번 달에 짠 코드는 다음과 같습니다.
class TicTacToe :
def __init__(self) :
self.board = [0] * 9
self.answer = [
[0, 1, 2], [3, 4, 5], [6, 7, 8],
[0, 3, 6], [1, 4, 7], [2, 5, 8],
[0, 4, 8], [2, 4, 6]]
self.winner = 0
self.player = -1
def print(self) :
for i in range(3) :
row = []
for j in range(3) :
item = self.board[3*i + j]
if item == 0 :
row.append(' ')
elif item == 1 :
row.append('O')
else :
row.append('X')
print(f'| {" | ".join(row)} |')
print('')
def move(self, num) :
if num < 0 or num > 8 or self.board[num] != 0 :
return False
self.board[num] = self.player
self.player *= -1
if self.check_win() :
if self.winner == 1 :
print("Player 1 Win!!")
elif self.winner == -1 :
print("Player 2 Win!!")
return True
else :
if not self.empty() :
print("Draw!!")
return True
self.player *= -1
return False
def check_win(self) :
for condition in self.answer :
if all(self.board[i] == 1 for i in condition) :
self.winner = 1
return True
elif all(self.board[i] == -1 for i in condition) :
self.winner = -1
return True
if not self.empty() :
self.winner = None
return True
def empty(self) :
if 0 in self.board :
return True
else :
return False
이 코드에서 바꿔야 할 점은 크게 가지가 있습니다.
1. 입력을 키패드로 받게 바꿔줌
지금은 test.move(5) 등의 코드를 직접 붙여넣어 제가 임의적으로 착수하고 있는데, 키패드로 입력하면 알아서 그 위치에 착수가 되도록 할 것입니다.
2. 기보 시스템
강화학습을 시키기 위해, 지금까지 착수한 모든 수들이 담겨있는 '기보'를 저장하는 시스템을 구축해야 합니다.
3. 승리 조건 확인 방법 변경
현재는 제가 3x3의 틱택토 판에서 승리할 수 있는 모든 조건들을 찾아 승리 조건에 넣어두었는데요. 추후에 3x3이 아니라 5x5 판에서도 학습을 시켜보는 등 연구를 확장하려면 제가 일일이 찾는 것보다는 프로그래밍으로 한 번에 승리 조건들을 찾는 것이 편합니다.
따라서 지금부터 이 3가지의 변경사항들을 변경해보겠습니다.
1. 키패드 입력
가장 먼저 키패드에서 입력을 받게 코드를 바꾸겠습니다. 우선, 입력을 받는 기능을 하는 함수를 따로 구현해주었습니다.
def get_input() :
n = input()
test.move(n)
원래 코드에서는 move 메서드에서 이동하고자 하는 칸이 유효한 값인지를 검사했는데, 이제는 입력을 받음과 동시에 유효한지를 확인하고, 아니라면 다시 입력하게 하는 방식으로 수정해주겠습니다. 먼저 move 메서드에서 유효한 값인지 확인하는 코드를 제거하였습니다. 또, 착수함과 동시에 보드를 출력하게 수정해주었습니다.
def move(self, num) :
# if num < 0 or num > 8 or self.board[num] != 0 :
# return False -> 이 두 줄 = 삭제
...
self.print() # -> 추가
이제 아까 짠 get_input 함수에 유효한 값인지를 확인하게 하는 코드들을 짜주었습니다. 확인 조건은 '1. 정수인가, 2. 1에서 9 사이의 수인가, 3. 비어있는 칸인가' 이렇게 3가지로 지정하였습니다. 또, 모든 조건을 통과하면 바로 착수하게 move 메서드가 실행되게 하였습니다. 또, 저희가 생각하는 건 1~9가 편하므로 리스트에서의 인덱스와 맞춰주기 위해 정수로 바꾼 입력값에서 1을 빼주었습니다.
def get_input() :
n = input()
if n.isdigit() :
n = int(n) - 1
if 0 <= n <= 8 :
if test.board[n] == 0 :
test.move(n)
else :
print("비어있는 칸에 착수하세요")
else :
print("착수할 수 있는 칸은 0에서 8 사이 수입니다")
else :
print("정수로 입력하세요")
코드 시작 시 실행될 코드도 변경해주었습니다. TicTacToe 클래스를 하나 만들고, 빈 보드를 한 번 출력한 뒤 승자가 나올때까지 입력을 받게 만들어주었습니다.
test = TicTacToe()
test.print()
while test.winner == 0 :
get_input()
의도한 대로 잘 작동하는지도 확인해보았습니다.
2. 기보 시스템 제작
이제 착수하는 모든 요소들을 담는 기보를 제작해보겠습니다. 그냥 간단하게 init 생성자 메서드 내에 기보 속성을 지정하고, 착수할 때마다 board 리스트를 저장하는 방식으로 제작하겠습니다.
먼저, 기보 속성을 지정하겠습니다.
def __init__(self) :
self.board = [0] * 9
...
self.player = -1
self.notation = [] # -> 추가
이후 착수시에 board를 notation 속성에 저장하게 하였습니다.
def move(self, num) :
...
self.player *= -1
self.notation.append(self.board) # -> 추가
...
그러나 이렇게 코드를 짜고 마지막에 기보를 출력하니 다음과 같은 문제가 발생했습니다.
0
3
1
4
2
-> notation : [[-1, -1, -1, 1, 1, 0, 0, 0, 0], [-1, -1, -1, 1, 1, 0, 0, 0, 0], [-1, -1, -1, 1, 1, 0, 0, 0, 0], [-1, -1, -1, 1, 1, 0, 0, 0, 0], [-1, -1, -1, 1, 1, 0, 0, 0, 0]]
왜 이런 문제가 발생했나를 찾아보니... notation에 board를 추가하게 되면 board의 주소가 참조되어 들어가기 때문에 board가 바뀌면 notation에 들어가있는 값들도 바뀌게 됩니다. 따라서 notation에는 board를 복사한 값을 집어넣음으로써 수정하였습니다.
def move(self, num) :
...
self.player *= -1
self.notation.append(self.board.copy()) # -> 추가
...
3. 승리 조건 확인 방법 변경
마지막 변경 사항입니다. 승리 조건 리스트를 프로그래밍을 통해 알아내도록 변경해보겠습니다. 우선 보드가 몇칸의 정사각형인지를 알아내야 하므로 칸 수를 알려주는 속성을 지정하고, board의 개수를 칸^2으로 지정해주었습니다.
def __init__(self) :
self.cell = 3
self.board = [0] * (self.cell)**2 # -> 이 두 줄 = 수정
...
이제 가로, 세로 승리 조건을 찾아보겠습니다. 단순한 for문으로 해결 가능합니다.
def __init__(self) :
...
self.answer = []
for i in range(self.cell) :
self.answer.append([i*self.cell + j for j in range(self.cell)]) # 가로 승리 조건
self.answer.append([j*self.cell + i for j in range(self.cell)]) # 세로 승리 조건
...
마지막으로 대각선 승리 조건을 찾아주겠습니다. (코드업의 이차원 배열을 풀기 위한 노가다들이 도움이 될 줄은 몰랐네요)
def __init__(self) :
...
self.answer.append([i*self.cell + i for i in range(self.cell)]) # 기울기 -1 대각선 승리 조건
self.answer.append([i*self.cell + self.cell-(i+1) for i in range(self.cell)]) # 기울기 1 대각선 승리 조건
...
또, 코드 내에 3x3에서 작동될 거라고 생각하고 짠 코드들의 3을 모두 self.cell로 고쳐주었습니다.
이렇게 현재 급한 변경사항들은 모두 변경하였습니다. 강화학습 시킬때도 조금씩 변경이 필요하긴 하겠지만 우선은 이 정도로 환경 구축을 마무리하도록 하겠습니다.
벌써 4주가 지났습니다. 수행평가와 시험공부 이슈로 인해 잠시 중단되었던 강화학습 개발을 이어가보도록 하겠습니다. 또, 지금부터 개발한 코드들은 일일이 설명하기엔 너무 많은 관계로 어떤 코드를 개발했는지만 간략히 소개하도록 하겠습니다.
먼저 큰 계획 변경이 일어났습니다. 원래는 두 에이전트를 만들고 이들을 경쟁시키며 학습시킬 계획이었으나 조사를 좀 하다보니 그게 여간 귀찮은 일이 아닌 걸 알아버렸습니다. 따라서 그냥 에이전트 하나만 학습시키고 나머지는 랜덤한 위치에 두게 함으로써 그 둘끼리 틱택토를 두게 해 학습시킬 생각입니다.
에이전트 개발
이후 본격적으로 개발을 시작하였습니다. 먼저, Agent 파일을 제작하였습니다. 이 파일은 에이전트에 관한 파일로, 학습률, 감가율, 입실론 등을 이용해 Agent를 정의하는 생성자와, q_value가 최대인 행동을 선택하는 함수, q_value를 조정해가는 함수 등이 포함되어 있습니다. 코드는 다음과 같습니다.
from collections import defaultdict
import numpy as np
class Agent() :
def __init__(self, env, alpha = 0.1, gamma = 0.9, epsilon = 0.9, epsilon_min = 0.1, epsilon_dacay = 0.95) :
self.env = env
self.alpha = alpha
self.gamma = gamma
self.epsilon = epsilon
self.epsilon_min = epsilon_min
self.epsilon_decay = epsilon_dacay
self.q_table = defaultdict(lambda : np.zeros(self.env.cell ** 2))
def choose_action(self, state):
available_actions = [i for i, v in enumerate(self.env.board) if v == 0]
if np.random.uniform() < self.epsilon:
action = np.random.choice(available_actions)
else:
if state not in self.q_table:
self.q_table[state] = np.zeros(self.env.cell ** 2)
q_values = self.q_table[state]
perm_actions = np.random.permutation(available_actions)
action = perm_actions[np.argmax([q_values[a] for a in perm_actions])]
return action
def learn(self, transition) :
s, a, r, next_s, done = transition
q_value = self.q_table[s][a]
if done :
q_target = r
else :
q_target = r + self.gamma * np.max(self.q_table[next_s])
self.q_table[s][a] += self.alpha * (q_target - q_value)
if self.epsilon > self.epsilon_min :
self.epsilon *= self.epsilon_decay
환경 재수정
또, 앞서 한 번 변경했던 환경 파일(TTT_Env)을 다시 수정해주었습니다. 플레이어1, 플레이어2를 구분할 수 있게 하고 보상을 설정하고 전이확률을 만드는 등 강화학습에 주가 되는 여러 코드들을 첨가하고, 기존의 코드들을 수정하거나 기타 자잘한 코드들을 추가하였습니다. 코드는 다음과 같습니다.
import random
from collections import defaultdict
class TicTacToe() :
def __init__(self, player_mode = '1p', print_mode = "Y") :
if player_mode == '1p':
self.mode = 1
elif player_mode == '2p':
self.mode = 2
else :
print("error - default mode : 1p")
self.mode = 1
if print_mode != "N" and print_mode != "Y":
self.print_mode = "N" #wrong input : defalut setting
else:
self.print_mode = print_mode
self.cell = 3
self.answer = [] # 승리 조건들
for i in range(self.cell) :
self.answer.append([i*self.cell + j for j in range(self.cell)])
self.answer.append([j*self.cell + i for j in range(self.cell)])
self.answer.append([i*self.cell + i for i in range(self.cell)])
self.answer.append([i*self.cell + self.cell-(i+1) for i in range(self.cell)])
self.reward_case = {"win" : 6.0,
"lose" : -2.0,
"draw" : -1.0,
"wrong_move" : -5.0,
"nothing" : 0.0}
n_state = 3**(self.cell**2)
n_action = self.cell**2
P = defaultdict(dict)
for s in range(n_state):
before_board = self.state2board(s)
temp_board = self.state2board(s)
P[s] = defaultdict(list)
for a in range(n_action):
temp_board[a] = 1
next_s = self.board2state(temp_board)
done, winner = self.check_win(temp_board)
if done:
if winner == 1:
r = self.reward_case["win"]
elif winner == -1:
r = self.reward_case["lose"]
elif winner == 0:
r = self.reward_case["draw"]
else:
r = self.reward_case["nothing"]
if before_board[a] != 0:
r = self.reward_case["wrong_move"]
else:
r = self.reward_case["nothing"]
if self.check_win(before_board)[0]:
game_over = True
next_s = s
else:
game_over = False
P[s][a] = [(1.0, next_s, r, game_over)]
self.reset()
self.print_board()
def reset(self) :
self.board = [0] * (self.cell)**2
self.winner = 0
self.player = 1
self.notation = []
def print_board(self) :
if self.print_mode == "N":
return
for i in range(self.cell) :
row = []
print('-------------')
for j in range(self.cell) :
item = self.board[self.cell*i + j]
if item == 0 :
row.append(' ')
elif item == 1 :
row.append('O')
else :
row.append('X')
print(f'| {" | ".join(row)} |')
print('-------------\n')
def move(self, action) :
before_empty = True
if self.board[action] != 0:
before_empty = False
self.board[action] = self.player
self.player *= -1
self.notation.append(self.board.copy())
done, self.winner = self.check_win(self.board)
reward = self.reward_case["nothing"]
if done :
if self.winner == 1 :
print("Player 1 Win!!")
reward = self.reward_case["win"]
elif self.winner == -1 :
print("Player 2 Win!!")
reward = self.reward_case["lose"]
else :
print("Draw!!")
reward = self.reward_case["draw"]
if not before_empty:
reward = self.reward_case["wrong_move"]
return (self.board2state(self.board), reward, done)
def check_win(self, board) :
for condition in self.answer :
if all(board[i] == 1 for i in condition) :
return (True, 1)
elif all(board[i] == -1 for i in condition) :
return (True, -1)
if not self.empty(board) :
return (True, 0)
else:
return (False, 0)
def empty(self, board) :
if 0 in board :
return True
else :
return False
def get_input(self) :
if self.mode == 1 and self.player == -1:
while(True):
n = random.randint(0, self.cell**2 - 1)
if self.board[n] == 0:
self.move(n)
break
else:
n = input()
if n.isdigit() :
n = int(n) - 1
if 0 <= n <= self.cell**2 - 1 :
if self.board[n] == 0 :
self.move(n)
else :
print("비어있는 칸에 착수하세요\n")
else :
print(f"착수할 수 있는 칸은 1에서 {self.cell**2} 사이입니다\n")
else :
print("정수로 입력하세요\n")
def board2state(self, board):
res = 0
for i in range(9):
res += board[i]*(3**i)
return res
def state2board(self, state):
res = [0]*9
for i in range(9):
res[i] = state%3
state == (int)(state/3)
return res
사실 강화학습은 알고리즘 코드는 구글 등에 돌아다니는게 많기 때문에 그걸 쓰면 되지만 환경은 그렇지 않기 때문에 환경 설정이 가장 중요한데, 이 때문인지 환경 설정 코드가 가장 복잡했던 것 같습니다.
알고리즘 구축
이후 드디어 q_learning 알고리즘을 구축했습니다. 사실 q_learning 코드 같은 경우에는 구글 등에 많이 있기도 하고, 제가 가지고 있는 자료에 기본적인 틀이 다 있어서 앞의 환경에 비하면 그렇게 어렵지 않았던 것 같습니다.
q_learning 알고리즘 파일은 episode 수만큼 반복하여 경기를 하며 q_learning을 진행하는 코드와 그 과정에서의 최종 보상, 승률 등을 그래프로 출력해주는 함수, 승률을 계산하는 코드 등으로 구성되어 있습니다.
from TTT_Env import TicTacToe
from agent import Agent
from collections import namedtuple
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(1)
Transition = namedtuple('Transition', ('state', 'action', 'reward', 'next_state', 'done'))
def Run_Q_Learning(agent, env, num_episode, p_mode = "N"):
history = []
for episode in range(num_episode):
state = env.reset()
final_reward, n_moves = 0.0, 0
while True:
action = agent.choose_action(state)
next_state, reward, done = env.move(action)
agent.learn(Transition(state, action, reward, next_state, done))
env.print_board()
state = next_state
n_moves += 1
if done:
final_reward = reward
break
history.append(final_reward)
if episode%1 == 0:
print('에피소드 %d: 보상 %.1f #이동 %d' %(episode, final_reward, n_moves))
return history
def plot_learning_history(history, env):
win_prob = win_prob_history(history, env)
fig = plt.figure(1, figsize=(14, 10))
ax = fig.add_subplot(2, 1, 1)
plt.plot(history, 'b.')
plt.xlabel('Episodes')
plt.ylabel('Final Rewards')
ax = fig.add_subplot(2, 1, 2)
plt.plot(win_prob)
plt.xlabel('Episodes')
plt.ylabel('Winning Probability')
plt.show()
def win_prob_history(history, env):
win_r = env.reward_case["win"]
res = []
win_n = 0
for i in range(len(history)):
if history[i] == win_r:
win_n += 1
res.append(win_n/(i+1))
return res
env = TicTacToe("1p", "N")
agent = Agent(env)
history = Run_Q_Learning(agent, env, 10000)
plot_learning_history(history, env)
이렇게 강화학습을 위한 모든 코드 제작이 끝났습니다. 이제 코드를 실행해보고 실행 결과를 보도록 하겠습니다.
실행 결과
코드를 실행한 결과 출력된 그래프들은 다음과 같습니다.
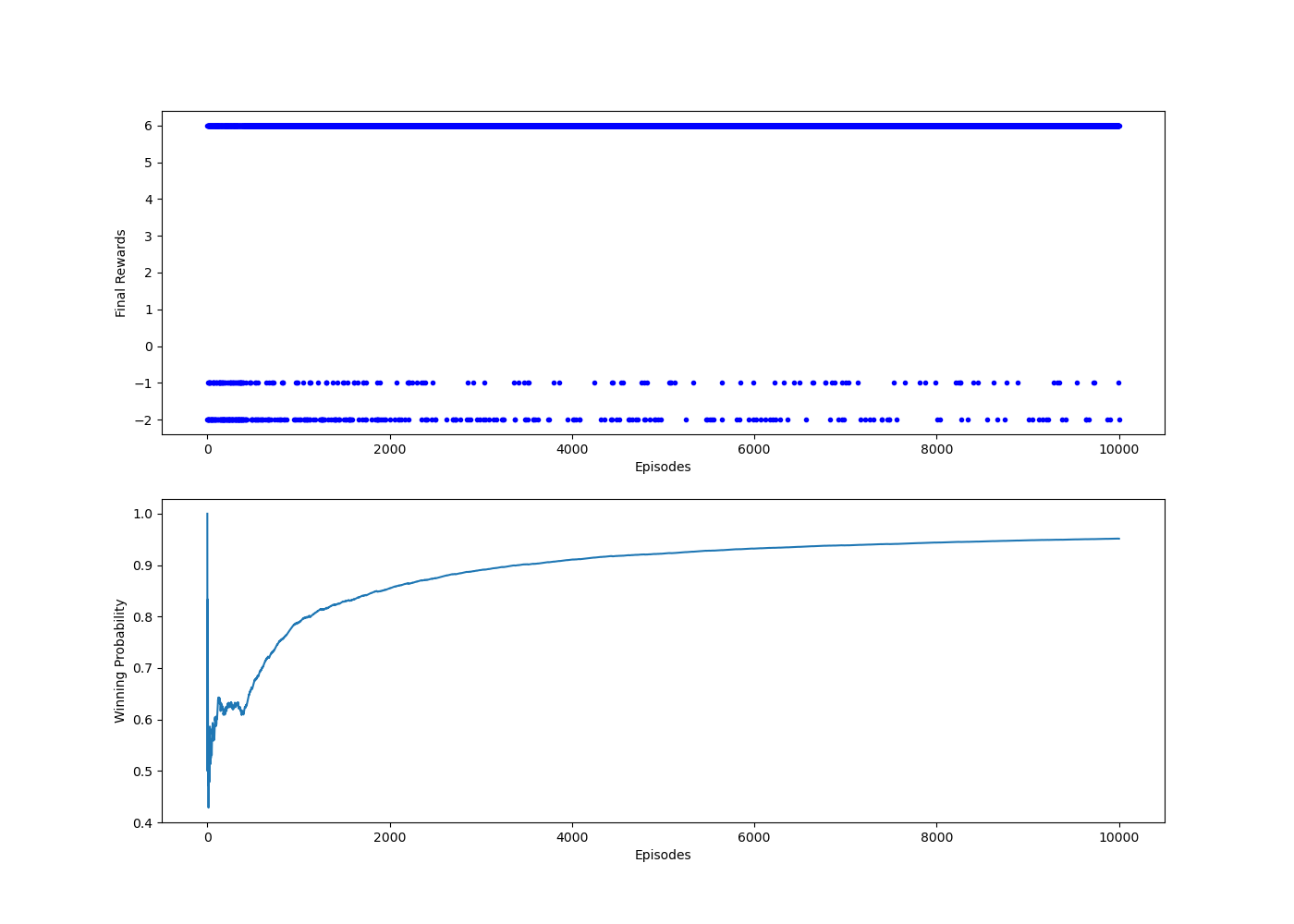
그래프를 잠깐 살펴보면 최종 보상이 6(승리), -1(무승부), -2(패배)로 구성되어있는데 그 중 에이전트 1이 승리한 경우 (6)가 압도적으로 많은 걸 살펴볼 수 있고, 승률도 계속해서 올라가는 것으로 보아 에이전트 1의 강화학습이 아주 잘 진행되었다고 볼 수 있을 것 같습니다.
이제 개발도 다 끝났으니 7월에는 제가 직접 학습시킨 모델과 틱택토를 두며 얼마나 학습되었는지를 확인해보고, 각 칸 별로 어떤 차이점이 있나 혹은 틱택토의 칸 수에 따라 필요한 학습 횟수 등등 다양한 요소들을 살펴볼 생각입니다.
'프로그래밍 > 틱택토 강화학습 (TTT-RL)' 카테고리의 다른 글
| 틱택토 강화학습 (Tik-Tak-Toe RL) - [심화 탐구] (2) | 2024.08.12 |
|---|---|
| 틱택토 강화학습 (Tik-Tak-Toe RL) - [정보과학융합탐구 - 7월 과제] (0) | 2024.07.09 |
| 틱택토 강화학습 (Tik-Tak-Toe RL) - [정보과학융합탐구 - 5월 과제] (4) | 2024.05.31 |
| 틱택토 강화학습 (Tik-Tak-Toe RL) - [정보과학융합탐구 - 4월 과제] (2) | 2024.04.13 |
| 틱택토 강화학습 (Tik-Tak-Toe RL) - [정보과학융합탐구 - 3월 과제] (1) | 2024.03.28 |



